Overview
During the Dec 2023 iteration. There were two cloud teams (BBY and DTC). Under their amazing work, we have upgraded the architecture significantly.
Final Cloud architecture for 2023
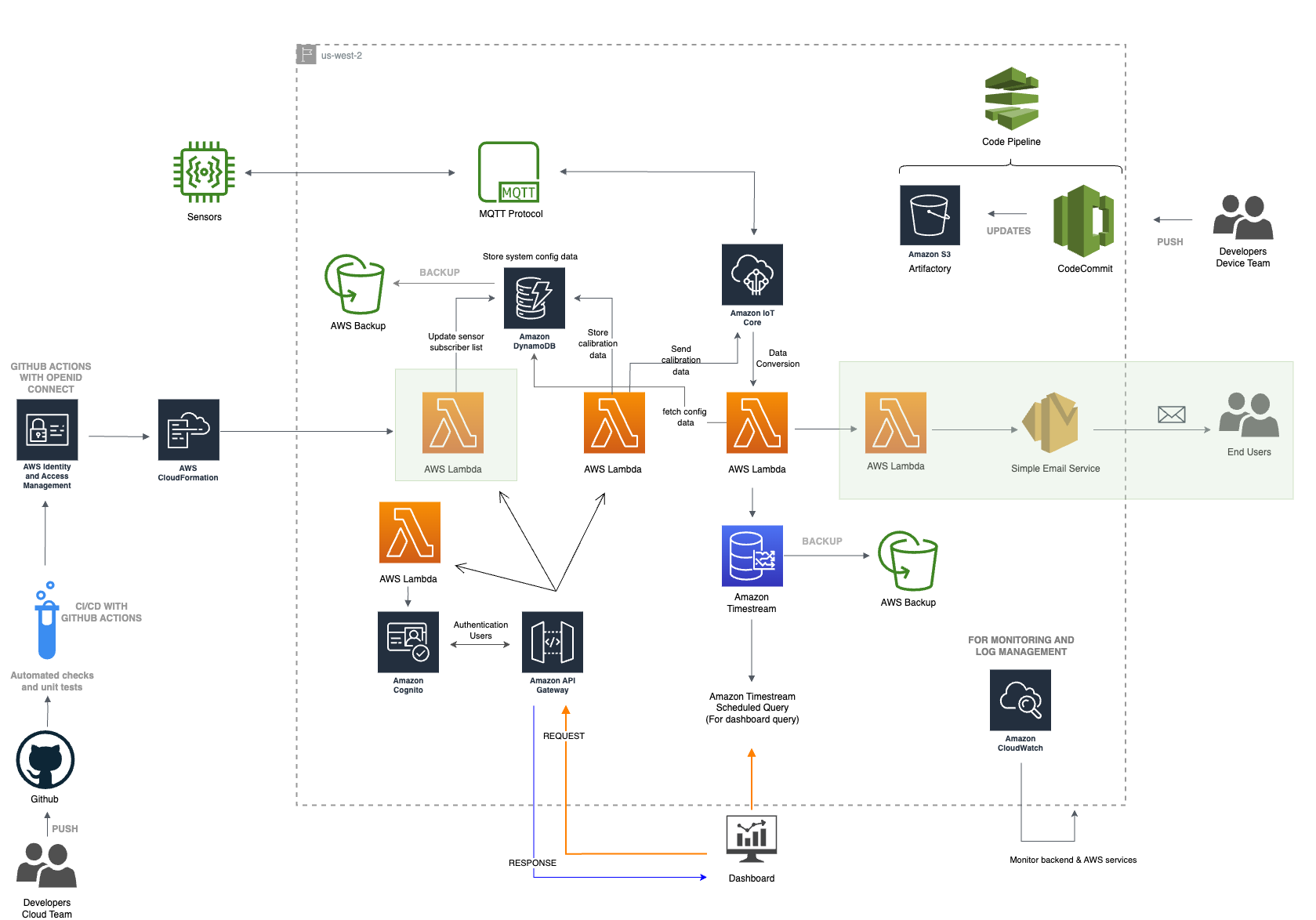
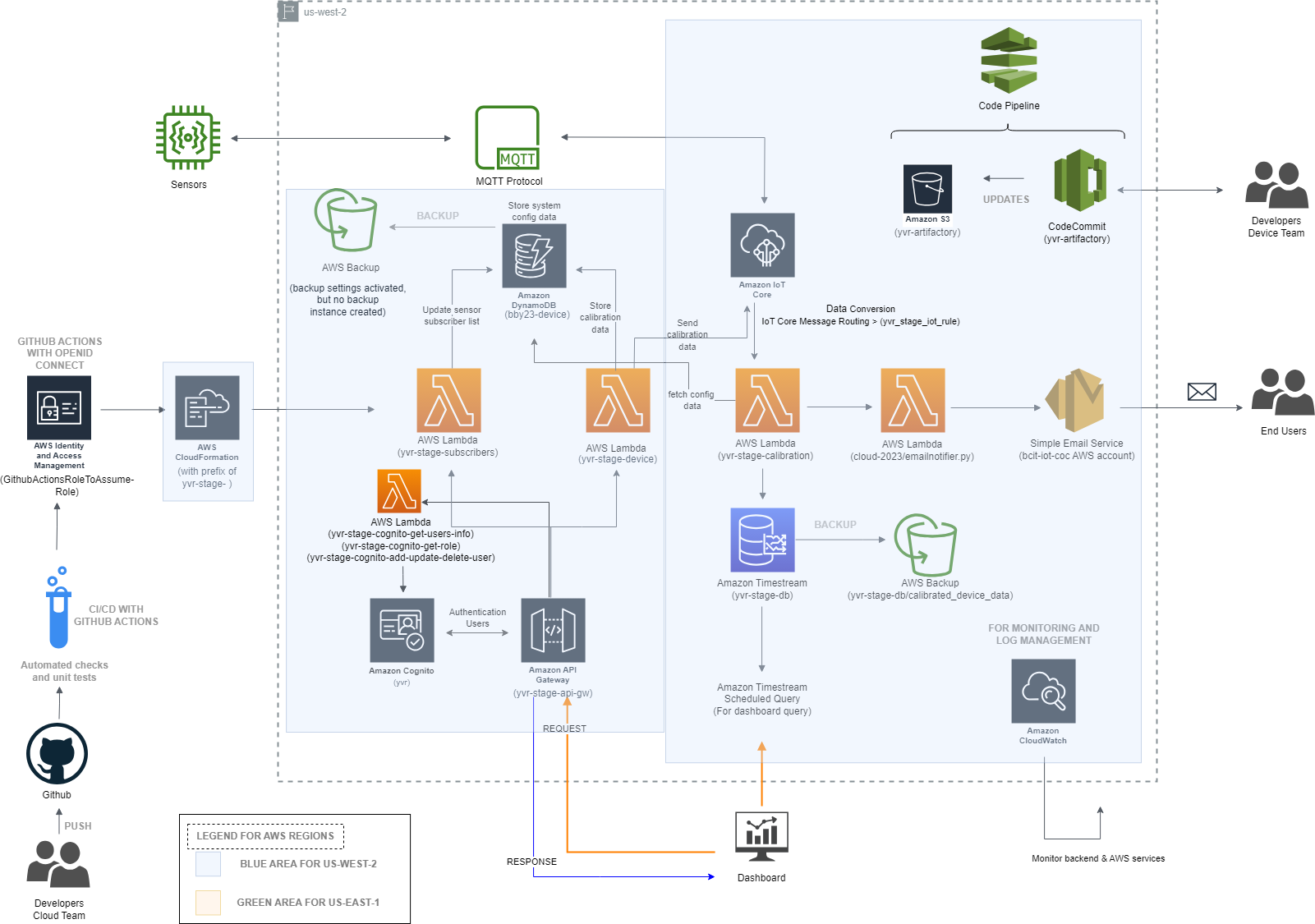
Final Cloud architecture for 2023 Annotated with Resource Names
The updated architectures aims to achieve:
- Improved security
- Cost optimization
- Removal of redundancies
- Improved backup and recoverability of timestream db and dynamodb
- Lambdas and Lambda Layers to process calibration data
- CI/CD of Lambdas
NOTE: Resources with prefixes
yvr-stageare the final stage resources that’ll be used. However, there is some fragmented architecture where APIG and some dynamo tables are located inus-east-1these are prefixed bybby23which are hooked up to the yvr-stage resources.
Key Features / Concepts:
The docs in this page isn’t going to go over how certain AWS resources work. There’s plenty of official docs on that already. The objective of this page is to showcase our design choices and why they make sense.
1. Why did we go severless?
Running services on AWS incurs a cost however it's easier to get started and infrastructure concerns are outsourced to AWS. There's not that big of a cost comparison between running a monolothic architecture in comparison to this severless architecture. Remember, if you choose to do monolithic, you have auto scaling concerns as well as instance sizes that might be needed. On top of that, there's added complexity.For a project that is passed from team to team, reducing complexity in architecture is a big selling point. In addition, if teams were stuck building our scalable, reliable, and secure infrastructure this project will likely never be finished do to the complexity.
2. Why microservices?
Microservices help make the certain features swappable and upgradeable without shutting down other parts of the system. In addition, we can scale and add more microservices/ lambdas to support newer business logic as the arise.3. What are the important decision criterias when building this?
1. security 2. cost 3. maintainability 4. does it get the job doneOpportunities for Improvement
- SES notification resources are ready however Dashboard needs to utilize them
- Device is sending to a singular topic. A topic must be able to idenitify which device it’s coming from and for what sensor so that calibration can grab the right config data (physical and digital values) from the config dyanmo db table
- Follow AWS guidelines in building out the SES notification system which may require having unsubscribe buttons from emails as well as dead letter channels and validation of proper emails
- Further refine the SES notification email feature so that we can avoid spam or handle the notifications in batches. For example, a series of results being outside of a threshold can lead to dozens of alert emails in an hour.
- Implement scheduled queries for common queries that Dashboard may make and coordinate with the dashboard team to have these implemented. Therefore, the ideal situation is to only query from scheduled query via aws-sdk and not the entire dataset. For example, the test databse of
EMA_YVRhas over 120k rows. When multiple devices and sensors are live, we’d be approach big data levels – millions of rows. - Hosting the dashboard’s backend of AWS so that it has no start-up latency. Frontend could still use the free tier of Netlify. Just make sure the domain has proper SSL certificates and is valid for HTTPS.
- Have dashboard utilize the
yvr-stage-subscriberslambda and APIG endpoint so that dashboard can maintain the email list. Also, to set what sensors and thresholds they’d like to be emailed for.
Current Usage
| AWS Resource | Description/Reasoning |
|---|---|
AWS Cognito | Outsources authentication and authorization concerns to AWS and helps save us development time for custom security measures. Security in this area is handled by AWS. This service can be expensive if theres hundreds or thousands of users (charges are based on monthly active users). For a water monitoring system we’re expecting about a dozen active users at most. Cost here would be about $5/month. |
Calibration Lambdas | This is a central piece in ensuring data is stored into timestream properly. Calibration is based on a finding the value two sets of given physical and digital values. These values are inputted into our config dyanmo table through the dashboard by a technician. Currently these are random values. Baked into the calibration lambda are lambda layers that are responsible for email notifications and retrieving physical and digital values from config table. To access the lambdas and lambdas layers, refer to cloud-2023 repo. This repo also has CI/CD setup already using Github Actions. |
MQTT and IoT Core | These are predominately handled by AWS, we simply have to connect devices and route traffic for a given topic to the respective calibration lambdas to process. |
Github Actions | For CI/CD of lambdas. This is maintained via Github Actions. See the cloud-2023 repo for the sample workflows. |
AWS Backup | When we first got this project, there was a frankenstein usage of kensis firehose outputting data into S3 buckets to back data up. The cost difference is minimal and the recoverability and reliability of simply using AWS Backup makes more sense. |
Cloud Watch | Handles the logging. Specifically, we can specify the log levels such as ERROR, INFO etc to make debugging lambdas and other cloud resources much easier |
API Gateway | We chose to use API gateway to handle incoming rest requests because its easy to map data and handle responses comes from dashboard. This also support our severless & microservices architecture. |
SES notification | SES currently uses production level access. In other words, it’s capable of sending emails to anyone in the world even if they’re not verified. AWS has strict guidelines regarding this. We may need to build out dead letter channels to handle failed deliveries and make an “unsubscribe” button on email messages. This will better help us align with AWS rules to avoid spam. Here are the credemtials to the email password and username (AWS Secret Manager) https://us-west-2.console.aws.amazon.com/secretsmanager/secret?name=yvr-stage-ses-email-sender-credentials®ion=us-west-2 Dynamodb stores an email list (yvr-stage-email-subscribers) for the emails that are subscribed to email alerts. You can use the subscriber-notification apig endpoint and lambda to add and delete emails from this db. |
Dashboard | Although it’s not something the cloud team manages, the dashboard is split into Backend and Frontend repos to make it all work. |
Timestream db | To query this, use AWS-SDK. Querying a timestream db with a rest api is possible but quite challenging due to its celluar architecture. |