Introduction
This document will cover the costs, benefits, and potential downfalls that may come with using scheduled queries which were introduced in late 2021.
The schedule query feature is a fully managed, serverless, scalable solution for computing and storing aggregates and other forms of preprocessed data. These scheduled queries are defined ourselves with specific inputs and the frequency the query must be run is included. Timestream will then automatically and periodically run the query and write the results into a destination table.
By implementing this feature in AWS, queries made from the dashboard team using SQL will be faster and more affordable. More details are outlined under the Benefits and Cost section.
How To Use
Before creating a scheduled query, ensure that a destination table has been set up in its appropriate database. This destination table will be populated with results of your scheduled query.
- Log in to AWS and navigate to the Amazon Timestream service.
-
On the left-hand navigation bar, select Scheduled queries.
- Click Create scheduled query on the top right to create a new query.
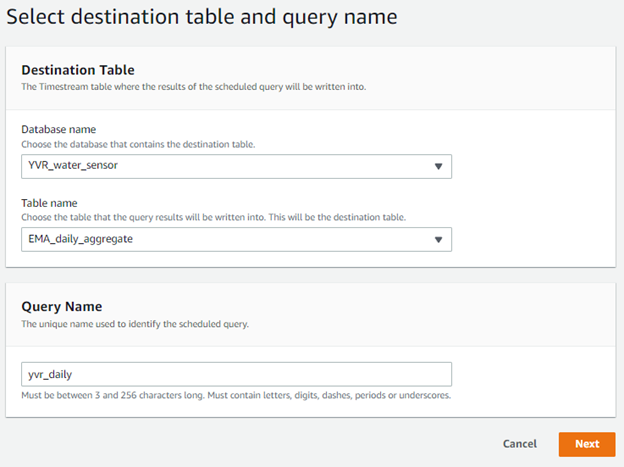
- Choose the preferred database to hold the destination table in and choose a table that the scheduled query results will be populated into.
-
Provide a descriptive query name to identify the scheduled query.
-
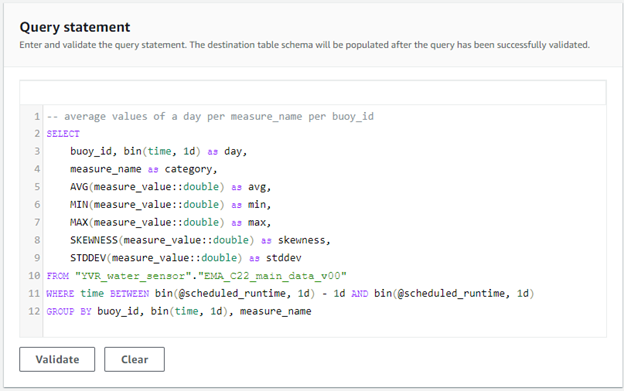
Define a query statement on the source table which will be scheduled by Timestream. The query statement below provides a daily aggregate of the average of all values of each measure name per buoy. Once entered, click Validate to automatically populate the destination table schema.
For more information, references have been made available at the bottom of this document under References.
-
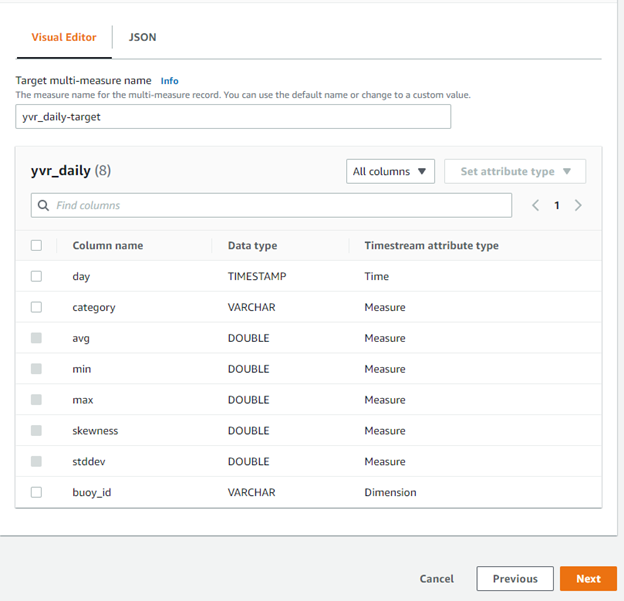
Using the visual editor, modify the Timestream attribute type for undefined or columns with incorrect types. There must be at least one column with type Dimension and must consist of a Time type as well (which will most likely be automatically generated for you). Please note, any changes made directly to the JSON will not be saved/reflected in the final confirmation screen.
-
Next, specify the schedule of the query. In the below example, we use a CRON expression which allows for more precise specifications (i.e., Trigger a scheduled query every hour only on Monday, Wednesdays, and Fridays), allowing us to trigger our query every day at midnight.
Otherwise, a fixed rate will suffice. For example, by setting the time frame to minute and the frequency to 5, the query will execute every 5 minutes after the creation of your scheduled query.
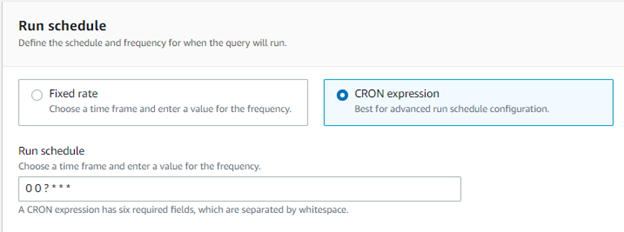
-
Next, select an IAM role, KMS key, SNS topic, and S3 bucket for the query. All components have been created prior to this document, therefore no further creations are necessary:
- IAM Role: EMA-timestream-scheduled-query-role
- AWS KMS Key: aws/timestream
- SNS Topic: timestream-scheduled-queries
- S3 Location: s3://timestream-scheduled-query-error-logs
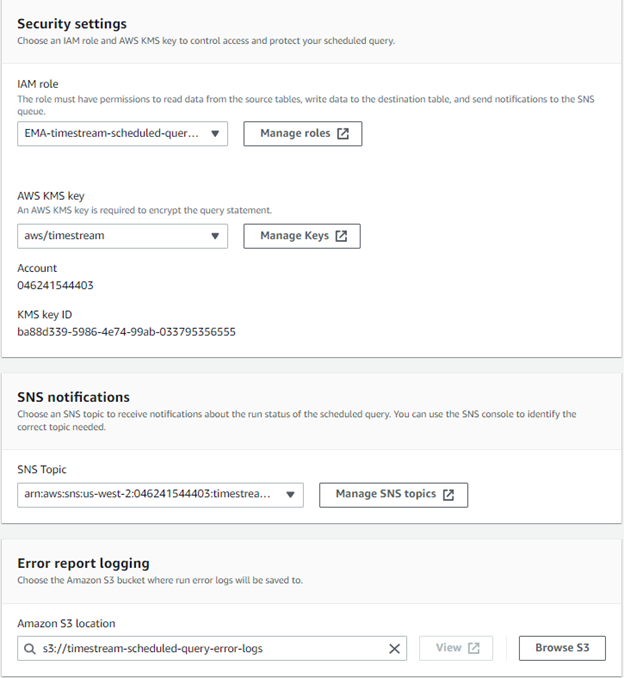
- Ensure query settings are correct and click Create to create a new scheduled query.
Errors
During the creation phase of a scheduled query, an error message stating “Failure - Network Failure” appears on the final step after clicking Create. Below is a checklist of some solutions that can be tried to remedy the problem, but to no avail. Further support from Rackspace may be required due to the current lack of resources that developers can refer to.
- IAM role for EMA-timestream-scheduled-query-role has been remade and checked to ensure appropriate policies have been attached (Full access for Timestream, SNS, and S3).
- SNS topic pub/sub is working correctly using an EMAIL protocol.
- S3 bucket has public access. Other properties should be the default settings.
- Using different browsers and incognito mode to create the scheduled query.
- Appropriate KMS key is used to encrypt and decrypt data during transit of Amazon Timestream data or when it’s at rest.
- Using Wireshark to trace logs in case packets are blocked during transit.
- Using AWS CLI to create and execute a scheduled query.
- Confirm settings regarding Network and Security Groups are correct in AWS VPC (Requires higher-level IAM permissions to access/modification)
Benefits
- Using scheduled queries lowers the impact of unintentional, long-running queries.
- Because scheduled queries populate a destination table, not a source table, we can allow for better data security by only allowing access to source tables by scheduled queries, and allowing access to destination tables for developers.
- Destination tables containing aggregated data will contain much less data than the original source table. This results in faster queries and cheaper storage.
- Can query destination tables using SQL, just as you would with a regular Timestream table.
- Such destination tables can have data retention policies attached to them as well to further optimize storage spending.
Cost
As mentioned in the Benefits section, destination tables that are populated by scheduled queries have cheaper storage than storing the data in the source table. Therefore, the data held within the destination table can be stored for much longer than if it were to be stored within the source table.
Recommendations
On the dashboard, a possible recommendation for a feature implementation would be to allow users to refresh the map and query the destination table for the latest information on all or a selection of sensors. Maybe tag the map with a Last Updated timestamp?
Another possible recommendation is to color code pins on the map itself for any detected skewed data, in addition to the notification system set up on the dashboard.
References
https://docs.aws.amazon.com/timestream/latest/developerguide/scheduledqueries.html
https://awsapichanges.info/archive/changes/d05708-query.timestream.html