Choosing The Appropriate Database
Initial Phase
The initial phase of the EMA Research Project used TimescaleDB, a relational database management system built on top of PostgreSQL and accessible via SQL. Integration with AWS is simple as data can be pipelined and normalized from AWS IoT Core to TimescaleDB using AWS Lambda which is triggered through IoT Rules.

On the client (dashboard) side of things, libraries are available to connect the client-side to TimescaleDB because of its utilization of PostgreSQL. Example code here.
| Pros | Cons |
|---|---|
| Full SQL | Fixed schema |
| Fast data ingestion, in other words, movement of data from one more sources to a destination to be stored and analyzed | Security and data privacy can be at risk |
| IP access control, controlling network access to TimescaleDB instance | |
| Better value at higher loads |

Current Phase
2022-05-16
The architecture below has been remodeled based on the initial architecture above.

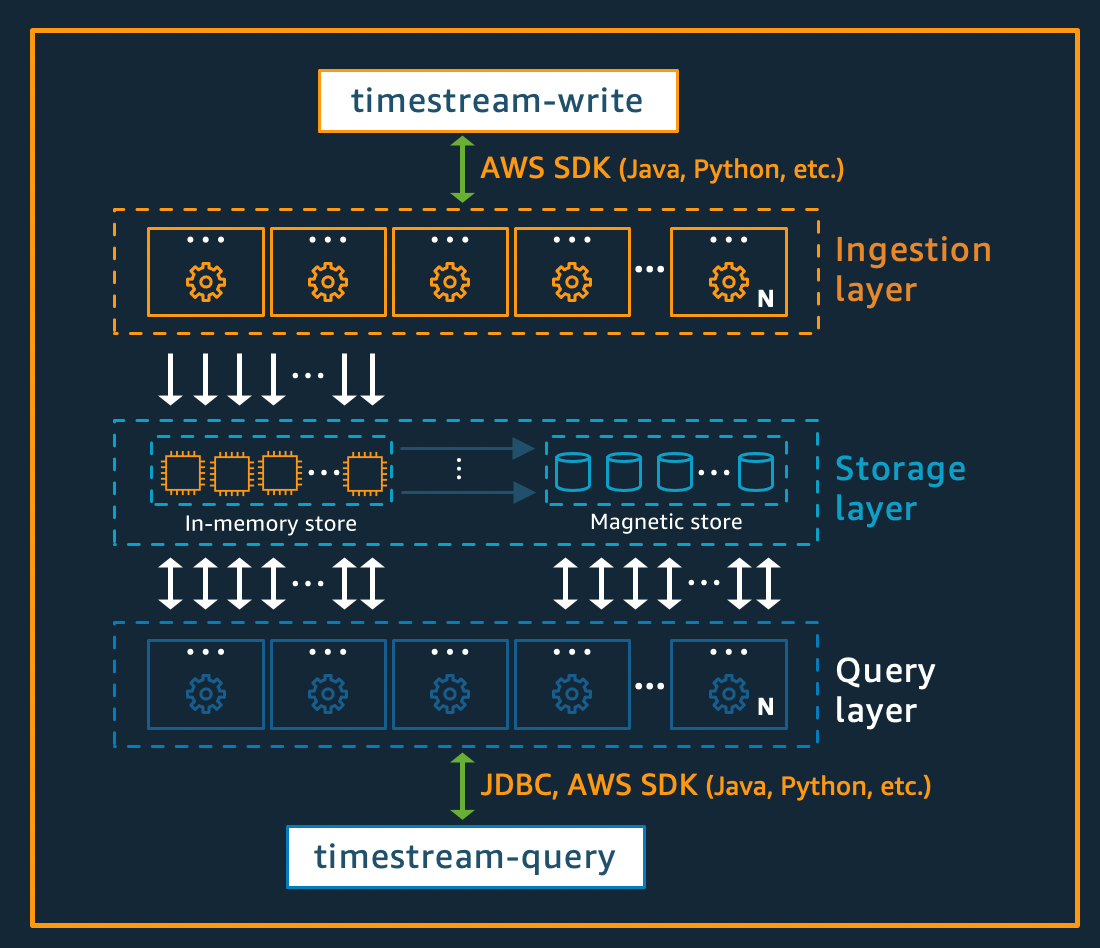
AWS Timestream
Amazom Timestream is purpose-built for IoT and operational systems due to it’s speed, scalability and cost effectiveness. Compared to a relational database, it can store/analyze big data (up to trillions of events) thousand times faster and at a tenth of the cost. In the following sections, we walk through how we decided to model the data, various sample queries, and setting data retention policies to optimize cost for our use case.
(https://docs.aws.amazon.com/timestream/latest/developerguide/metering-and-pricing.queries.html)
For a step-by-step walkthrough on how to create a database, table, or query using the AWS Management Console click the following link: (https://docs.aws.amazon.com/timestream/latest/developerguide/console_timestream.html)
Key Concepts
- Time series - a sequence of records over a time interval
- Record - a single data point
- Dimension - attribute describing metadata
- Timestamp - indicates when the measure was collected or ingested
- Table - container for related time series with timestamp, dimensions, and measures
- Database - container for all tables
Best Practices: Data Modeling
As of November 30, 2021, AWS introduced an alternative to single-measure records called multi-measure records, as well as two new faster and more cost-effective capabilities called scheduled queries and magnetic storage writes.
Multi-measure records:
- Most suitable for multiple metrics that occur at the same timestamp
- All measures from the same timestamp appear as different columns stored in the same row
Single-measure records:
We are using single-measure records for guaranteed scalability when adding more sensors to the edge devices.
- Most suitable for when metrics occur at different time periods (ex. new record is written every time the pH dips below 6.5)
- Each measure has its own timestamp and is stored as its own record in Timestream
- Using multi-measure records and having both device and dashboard teams publish and subscribe to a general topic instead of a specific topic pertaining to a particular device id
https://docs.aws.amazon.com/timestream/latest/developerguide/data-modeling.html
Sample Queries
The following queries can be tested directly in the AWS Timestream Query Editor. Queries with projections and predicates including time ranges, measure names, and/or dimension names enable the query processing engine to prune a significant amount of data and help with lowering query costs.

Create SQL query to list all unique device IDs
SELECT * FROM "YVR_water_sensor"."EMA_C22_main_data_v00"
WHERE time BETWEEN ago(365d) AND now()
SELECT distinct deviceSELECT *,
MAX(time) as "most_recent_time"
FROM "YVR_water_sensor"."EMA_C22_main_data_v00"
WHERE buoy_id = '1'
GROUP BY buoy_id,
measure_name,
time,
measure_value::double,
measure_value::booleanId
FROM "YVR_water_sensor"."EMA_C22_main_data"
Create SQL query one device - all metrics - current
SELECT *,
MAX(time) as "most_recent_time"
FROM "YVR_water_sensor"."EMA_C22_main_data_v00"
WHERE buoy_id = '1'
GROUP BY buoy_id,
measure_name,
time,
measure_value::double,
measure_value::boolean
Create SQL query for all devices - all metrics - current
SELECT *,
MAX(time) as "most_recent_time"
FROM "YVR_water_sensor"."EMA_C22_main_data_v00"
GROUP BY buoy_id,
measure_name,
time,
measure_value::double,
measure_value::boolean
Create SQL query to display one device - one metric - historic
SELECT * FROM "YVR_water_sensor"."EMA_C22_main_data_v00"
WHERE buoy_id = '1'
AND measure_name = 'ph'
Create SQL query to list all devices - one metric - historic
SELECT * FROM "YVR_water_sensor"."EMA_C22_main_data_v00"
WHERE measure_name = 'ph'
Create SQL query to list some devices - one metric - historic
SELECT * FROM "YVR_water_sensor"."EMA_C22_main_data_v00"
WHERE measure_name = 'ph'
AND buoy_id IN ('1', '2')
Create SQL query to list all devices - all metrics- Time frame of DAYS
SELECT * FROM "YVR_water_sensor"."EMA_C22_main_data_v00"
WHERE time BETWEEN ago(365d) AND now()
Create SQL query to list all devices - one metric, limited of 5 records- Time frame of days
SELECT * FROM "YVR_water_sensor"."EMA_C22_main_data_v00"
WHERE time BETWEEN ago(365d) AND now()
ORDER BY time DESC LIMIT 5
Create SQL query to list all devices - all metrics- between 2 time frames of HOURS
--Get all data from 6 hours ago til now
SELECT * FROM "YVR_water_sensor"."EMA_C22_main_data_v00"
WHERE time BETWEEN ago(6h) and now()
Create SQL query to list all devices - one metric- Time frame of HOURS
--Get all temperature data from the past 24 hours
SELECT * FROM "YVR_water_sensor"."EMA_C22_main_data_v00"
WHERE measure_name = 'temp' AND time >= ago(24h)
Create SQL query to give back data within a time frame of MINUTES
SELECT * FROM "YVR_water_sensor"."EMA_C22_main_data_v00"
WHERE time BETWEEN ago(10m) and now()
In the future, this can become a scheduled query depending on how often we want to receive data from the device team. We recommend specifying the names/attributes of the needed measures when more sensors are added to prevent adding unnecessary bytes to the queries
Best Practices: Data Retention
AWS offers data storage tiering and supports two storage tiers: a memory store and a magnetic store.
- Memory store: Optimized for point-in-time queries; shows how data has changed over a period of time. Typically, these queries process small amounts of recent data that has been sent to Timestream
- Magnetic store: Optimized for fast analytical queries and its purpose is more for long-term data storage. These queries process medium to large volumes of data
As of November 2021, AWS now offers magnetic storage writes. This allows us to write late arrival data into the magnetic store in the case of intermittent connectivity of our IoT sensors. Late arrival data is data with a timestamp that is in the past. Now, instead of maintaining a larger data retention period to process late arrival for memory store, we can set the the memory store data retention period to match the high throughput data ingestion requirements. This is highly suggested to be enabled as we can optimize our data storage spend.
Price per GB
| Memory Store | Magnetic Store | | — | — | | $0.036/hour | $0.03/month |
How To Set Data Retention Periods
- Go to Amazon Timestream
- Select your table and click Edit

- Set your memory and magnetic store retention accordingly. As of Spring 2022, the memory store retention is currently set to 24 hours and the magnetic store retention is set to the maximum of 73,000 days before permanent deletion.

-
Magnetic storage writes (above) are currently enabled. In the case of errors occurring during magnetic storage writes (asynchronous operation), an S3 location can be specified for error logs to be written to. This should be considered and integrated as the project scales further.
-
Press Save to save your changes.
Notes
- Data transfer is permanent from memory to magnetic store. Timestream does not populate the memory store from magnetic store. Be aware when decreasing the retention period of the memory store.
- Data deleted from magnetic store is permanent.
- If increasing the retention period of the memory or magnetic store, the change takes effect for data being sent to Timestream from that point onwards.
- Example: If original retention period of memory was 2 hours and increased to 24 hours, it will take 22 hours for memory store to contain 24 hours worth of data.
Storage Layer Overview
In the next section, we will go over how the client application (dashboard) can query and populate the front end with data with AWS SDK.